Chapter 5: Mobile Core
The Mobile Core provides IP connectivity to the RAN. It authenticates UEs as they connect, tracks them as they move from one base station to another, ensures that this connectivity fulfills the promised QoS requirements, and meters usage for billing.
Historically, all of these functions were provided by one or more proprietary network appliances. But like the rest of the 5G mobile network, these appliances are being disaggregated and implemented as a set of cloud services, with the goal of improving feature velocity for new classes of applications. It is also the case that as the range of use cases grows more diverse, a one-size-fits-all approach will become problematic. The expectation is that it should be possible to customize and specialize the Mobile Core on a per-application basis.
This chapter introduces the functional elements of the Mobile Core, and describes different strategies for implementing that functionality.
5.1 Identity Management
There are two equally valid views of the Mobile Core. The Internet-centric view is that each local instantiation of the Mobile Core (e.g., serving a metro area) acts as a router that connects a physical RAN (one of many possible access network technologies, not unlike WiFi) to the global Internet. In this view, IP addresses serve as the unique global identifier that makes it possible for any RAN-connected device to communicate with any Internet-addressable device or service. The 3GPP-centric view is that a distributed set of Mobile Cores (interconnected by one or more backbone technologies, of which the Internet is just one example) cooperate to turn a set of physical RANs into one logically global RAN. In this perspective, the IMSI burned into a device’s SIM card serves as the global identifier that makes it possible for any two mobile devices to communicate with each other.
Both of these perspectives are correct, but since broadband communication using Internet protocols to access cloud services is the dominant use case, this section takes an Internet-centric perspective of the Mobile Core. But before getting to that, we first need to understand several things about the 3GPP-centric perspective.
For starters, we need to be aware of the distinction between “identity” and “identifier”. The first term is commonly used when talking about principals or users, and the second term is used when talking about abstract objects or physical devices. Unfortunately, the two terms are conflated in the 3GPP architecture: The acronym IMSI explicitly includes the word “Identity”, where the “S” in both IMSI and SIM stands for subscriber (a kind of principal), yet the IMSI is also used as a global identifier for a UE connected to the mobile network. This conflation breaks down when there could be tens or hundreds of IoT devices for every customer, with no obvious association among them. Accounting for this problem is an “architecture alignment” fix we discuss in the next chapter when we describe how to provide Private 5G Connectivity as a managed cloud service.
If we take the view that an IMSI is primarily a global identifier for UEs, then we can think of it as the mobile network’s equivalent of a 48-bit 802.3 or 802.11 MAC address. This includes how addresses are assigned to ensure uniqueness: (MCC, MNC) pairs are assigned by a global authority to every MNO, each of which then decides how to uniquely assign the rest of the IMSI identifier space to devices. This approach is similar to how network vendors are assigned a unique prefix for all the MAC addresses they configure into the NIC cards and WiFi chips they ship, but with one big difference: It is the MNO, rather than the vendor, that is responsible for assigning IMSIs to SIM cards. This makes the IMSI allocation problem closer to how the Internet assigns IP addresses to end hosts, but unlike DHCP, the IMSI-to-device binding is static.
This is important because, unlike 802.11 addresses, IMSIs are also intended to support global routing. (Here, we are using a liberal notion of routing—to locate an object—and focusing on the original 3GPP-perspective of the global RAN in which the Internet is just a possible packet network that interconnects Mobile Cores.) A hierarchically distributed database maps IMSIs onto the collection of information needed to forward data to the corresponding device. This includes a combination of relatively static information about the level of service the device expects to receive (including the corresponding phone number and subscriber profile/account information), and more dynamic information about the current location of the device (including which Mobile Core, and which base station served by that Core, currently connects the device to the global RAN).
This mapping service has a name, or rather, several names that keep changing from generation to generation. In 2G and 3G it was called HLR (Home Location Registry). In 4G the HLR maintains only static information and a separate HSS (Home Subscriber Server) maintains the more dynamic information. In 5G the HLR is renamed the UDR (Unified Data Registry) and the HSS is renamed UDM (Unified Data Management). We will see the UDM in Section 5.2 because of the role it plays within a single instance of the Mobile Core.
There are, of course, many more details to the process—including how to find a device that has roamed to another MNO’s network—but conceptually the process is straightforward. (As a thought experiment, imagine how you would build a “logically global WiFi” using just 802.11 addresses, rather than depending on the additional layer of addressing provided by IP.) The important takeaway is that IMSIs are used to locate the Mobile Core instance that is then responsible for authenticating the device, tracking the device as it moves from base station to base station within that Core’s geographic region, and forwarding packets to/from the device.
Two additional observations about the relationship between IMSIs and IP addresses are worth highlighting. First, the odds of someone trying to “call” or “text” an IoT device, drone, camera, or robot are virtually zero. It is the IP address assigned to each device (by the local Mobile Core) that is used to locate (route packets to) the device. In this context, the IMSI plays exactly the same role in a physical RAN as an 802.11 address plays in a LAN, and the Mobile Core behaves just like any access router.
Second, whether a device connects to a RAN or some other access network, it is automatically assigned a new IP address any time it moves from one coverage domain to another. Even for voice calls in the RAN case, ongoing calls are dropped whenever a device moves between instantiations of the Mobile Core (i.e., uninterrupted mobility is supported only within the region served by a given Core). This is typically not a problem when the RAN is being used to deliver broadband connectivity because Internet devices are almost always clients requesting a cloud service; they just start issuing requests with their new (dynamically assigned) IP address.
5.2 Functional Components
The 5G Mobile Core, which 3GPP calls the 5GC, adopts a microservice-like architecture officially known as the 3GPP Service Based Architecture. We say “microservice-like” because while the 3GPP specification spells out this level of disaggregation, it is really just describing a set of functional blocks and not prescribing an implementation. In practice, a set of functional blocks is very different from the collection of engineering decisions that go into designing a microservice-based system. That said, viewing the collection of components shown in Figure 34 as a set of microservices is a reasonable working model (for now).
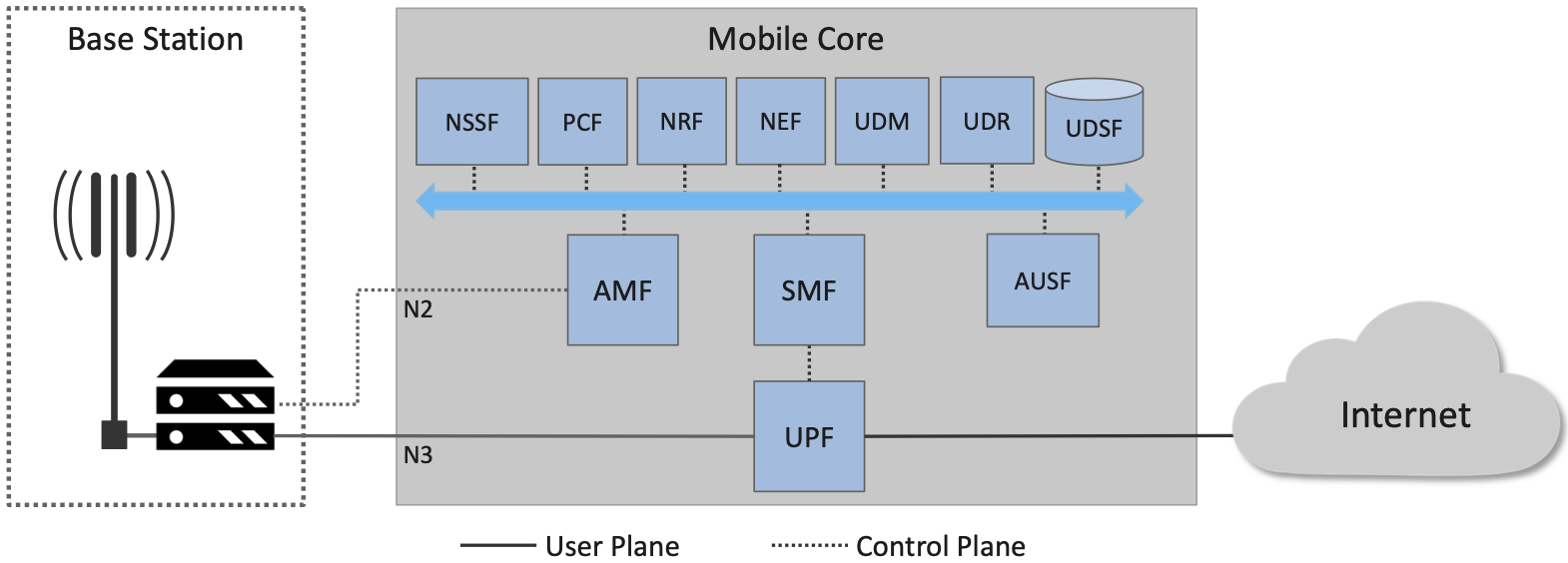
Figure 34. 5G Mobile Core (5GC), represented as a collection of microservices, where 3GPP defines the interfaces connecting the Mobile Core CP and UP to the RAN (denoted N2 and N3, respectively).
Starting with the User Plane (UP), the UPF (User Plane Function) forwards traffic between the RAN and the Internet. In addition to IP packet forwarding, the UPF is responsible for policy enforcement, lawful intercept, traffic usage measurement, and QoS policing. These are all common functions in access routers, even if they go beyond what you usually find in enterprise or backbone routers. The other detail of note is that, because the RAN is an overlay network, the UPF is responsible for tunneling (i.e., encapsulating and decapsulating) packets as they are transmitted to and from base stations over the N3 interface (as depicted in Figure 10 of Section 2.3).
The rest of the functional elements in Figure 34 implement the Control Plane (CP). Of these, two represent the majority of the functionality that’s unique to the Mobile Core CP (as sketched in Figure 13 of Section 2.4):
AMF (Access and Mobility Management Function): Responsible for connection and reachability management, mobility management, access authorization, and location services.
SMF (Session Management Function): Manages each UE session, including IP address allocation, selection of associated UP function, control aspects of QoS, and control aspects of UP routing.
In other words, the AMF authorizes access when a UE first connects to one of the local base stations, and then tracks (but does not control) which base station currently serves each UE. The SMF then allocates an IP address to each AMF-authorized UE, and directly interacts with the UPF to maintain per-device session state.
Of particular note, the per-UE session state controlled by the SMF (and implemented by the UPF) includes a packet buffer in which packets destine to an idle UE are queued during the time the UE transitions to active state. This feature was originally designed to avoid data loss during a voice call, but its value is less obvious when the data is an IP packet since end-to-end protocols like TCP are prepared to retransmit lost packets. On the other hand, if idle-to-active transitions are too frequent, they can be problematic for TCP.
Before continuing with our inventory of control-related elements in Figure 34, it is important to note we show only a fraction of the full set that 3GPP defines. The full set includes a wide range of possible features, many of which are either speculative (i.e., identify potential functionality) or overly prescriptive (i.e., identify well-known cloud native microservices). We limit our discussion to functional elements that provide value in the private 5G deployments that we focus on. Of these, several provide functionality similar to what one might find in any microservice-based application:
AUSF (Authentication Server Function): Authenticates UEs.
UDM (Unified Data Management): Manages user identity, including the generation of authentication credentials and access authorization.
UDR (Unified Data Repository): Manages user static subscriber-related information.
UDSF (Unstructured Data Storage Function): Used to store unstructured data, and so is similar to a key-value store.
NEF (Network Exposure Function): Exposes select capabilities to third-party services, and so is similar to an API Server.
NRF (Network Repository Function): Used to discover available services (network functions), and so is similar to a Discovery Service.
The above list includes 3GPP-specified control functions that are, in some cases, similar to well-known microservices. In such cases, substituting an existing cloud native component is a viable implementation option. For example, MongoDB can be used to implement a UDSF. In other cases, however, such a one-for-one swap is not possible due to assumptions 3GPP makes. For example, AUSF, UDM, UDR, and AMF collectively implement a Authentication and Authorization Service, but an option like OAuth2 could not be used in their place because (a) UDM and UDR are assumed to be part of the global identity mapping service discussed in Section 5.1, and (b) 3GPP specifies the interface by which the various components request service from each other (e.g., AMF connects to the RAN via the N2 interface depicted in Figure 34). We will see how to cope with such issues in Section 5.3, where we talk about implementation issues in more detail.
Finally, Figure 34 shows two other functional elements that export a northbound interface to the management plane (not shown):
PCF (Policy Control Function): Manages the policy rules for the rest of the Mobile Core CP.
NSSF (Network Slice Selection Function): Manages how network slices are selected to serve a given UE.
Keep in mind that even though 3GPP does not directly prescribe a microservice implementation, the overall design clearly points to a cloud native solution as the desired end-state for the Mobile Core. Of particular note, introducing a distinct storage service means that all the other services can be stateless, and hence, more readily scalable.
5.3 Control Plane
This section describes two different strategies for implementing the Mobile Core CP. Both correspond to open source projects that are available for download and experimentation.
5.3.1 SD-Core
Our first example, called SD-Core, is a nearly one-for-one translation of the functional blocks shown in Figure 34 into a cloud native implementation. A high-level schematic is shown in Figure 35, where each element corresponds to a scalable set of Kubernetes-hosted containers. We include this schematic even though it looks quite similar to Figure 34 because it highlights four implementation details.
Further Reading
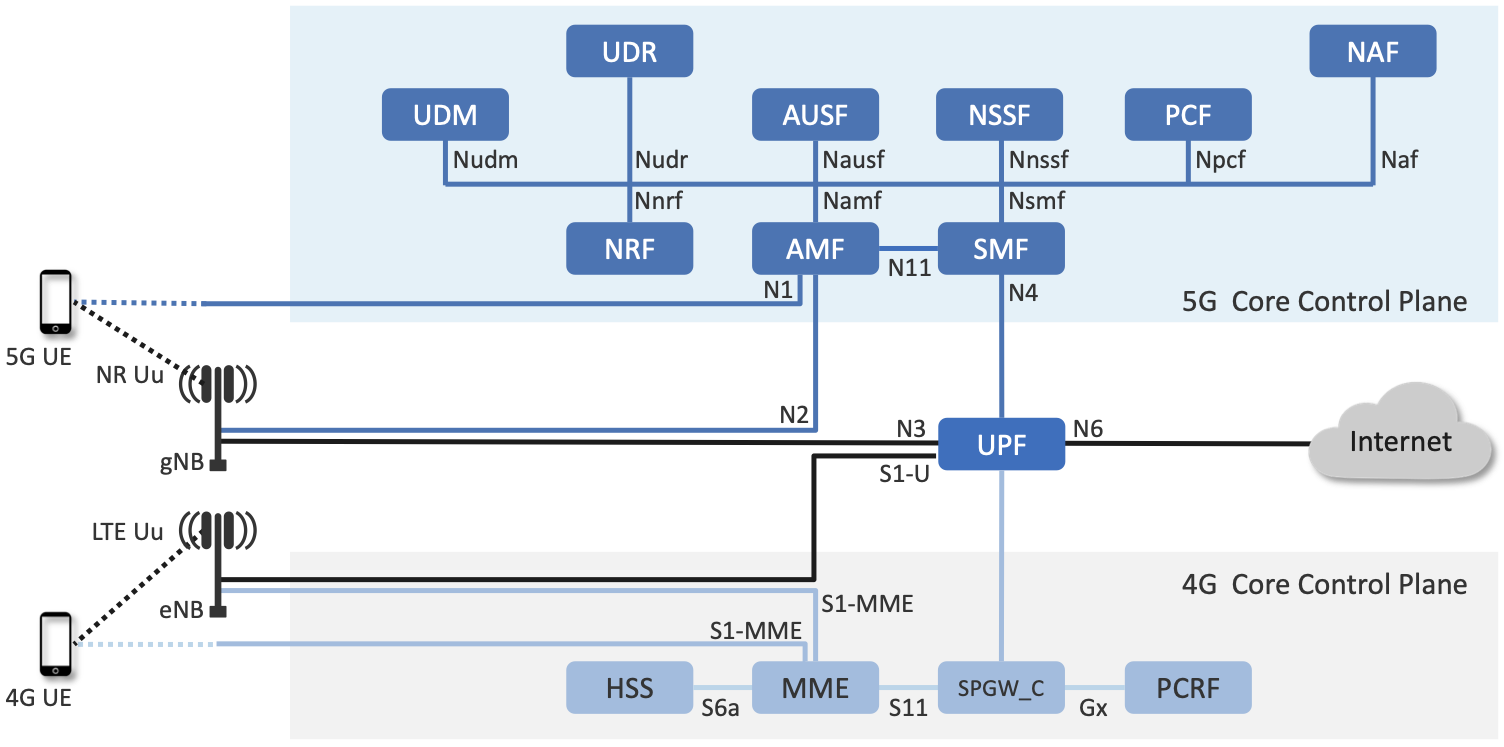
Figure 35. SD-Core implementation of the Mobile Core Control Plane, including support for Standalone (SA) deployment of both 4G and 5G.
First, SD-Core supports both the 5G and 4G versions of the Mobile Core,1 which share a common User Plane (UPF). We have not discussed details of the 4G Core, but observe that it is less disaggregated. In particular, the components in the 5G Core are specified so that they can be stateless, simplifying the task of horizontally scaling them out as load dictates. (The rough correspondence between 4G and 5G is: MME-to-AMF, SPGW_C-to-SMF, HSS-to-UDM, and PCRF-to-PCF.) Although not shown in the schematic, there is also a scalable key-value store microservice based on MongoDB. It is used to make Core-related state persistent for the Control Planes; for example, UDM/UDR (5G) and HSS (4G) write subscriber state to MongoDB.
- 1
SD-Core’s 4G Core is a fork of the OMEC project and its 5G Core is a fork of the Free5GC project.
Second, Figure 35 illustrates 3GPP’s Standalone (SA) deployment option, in which 4G and 5G networks co-exist and run independently. They share a UPF implementation, but UPF instances are instantiated separately for each RAN/Core pair, with support for both the 4G and 5G interfaces, denoted S1-U and N3, respectively. Although not obvious from the SA example, 3GPP defines an alternative transition plan, called NSA (Non-Standalone), in which separate 4G and 5G RANs were paired with either a 4G Core or a 5G Core. The details of how that works are not relevant to this discussion, except to make the point that production networks almost never get to enjoy a “flag day” on which a new version is universally substituted for an old version. A migration plan has to be part of the design. More information on this topic can be found in a GSMA Report.
Further Reading
Road to 5G: Introduction and Migration. GSMA Report, April 2018.
Third, Figure 35 shows many of the 3GPP-defined inter-component interfaces. These include an over-the-air interface between base stations and UEs (NR Uu), control interfaces between the Core and both UEs and base stations (N1 and N2, respectively), a user plane interface between the Core and base stations (N3), and a data plane interface between the Core and the backbone network (N6).
The schematic also shows interfaces between the individual microservices that make up the Core’s Control Plane; for example, Nudm is the interface to the UDM microservice. These latter interfaces are RESTful, meaning clients access each microservice by issuing GET, PUT, POST, PATCH, and DELETE operations over HTTP, where a service-specific schema defines the available resources that can be accessed. Note that some of these interfaces are necessary for interoperability (e.g., N1 and N Uu make it possible to connect your phone to any MNO’s network), but others could be seen as internal implementation details. We’ll see how Magma takes advantage of this distinction in the next section.
Fourth, by adopting a cloud native design, SD-Core benefits from being able to horizontally scale individual microservices. But realizing this benefit isn’t always straightforward. In particular, because the AMF is connected to the RAN by SCTP (corresponding to the N1 and N2 interfaces shown in Figure 35), it is necessary to put an SCTP load balancer in front of the AMF. This load balancer terminates the SCTP connections, and distributes requests across a set of AMF containers. These AMF instances then depend on a scalable backend store (specifically MongoDB) to read and write shared state.
5.3.2 Magma
Magma is an open source Mobile Core implementation that takes a different and slightly non-standard approach. Magma is similar to SD-Core in that it is implemented as a set of microservices, but it differs in that it is designed to be particularly suitable for remote and rural environments with poor backhaul connectivity. This emphasis, in turn, leads Magma to (1) adopt an SDN-inspired approach to how it separates functionality into centralized and distributed components, and (2) factor the distributed functionality into microservices without strict adherence to all the standard 3GPP interface specifications. This refactoring is also a consequence of Magma being designed to unify 4G, 5G, and WiFi under a single architecture.
One of the first things to note about Magma is that it takes a different view of “backhaul” from the approaches we have seen to date. Whereas the backhaul networks shown previously connect the eNBs/gNBs and radio towers back to the mobile core (Figure 3), Magma actually puts much of the mobile core functionality right next to the radio as seen in Figure 37. It is able to do this because of the way it splits the core into centralized and distributed parts. So Magma views “backhaul” as the link that connects a remote deployment to the rest of the Internet (including the central components), contrasting with conventional 3GPP usage. As explored further below, this can overcome many of the challenges that unreliable backhaul links introduce in conventional approaches.
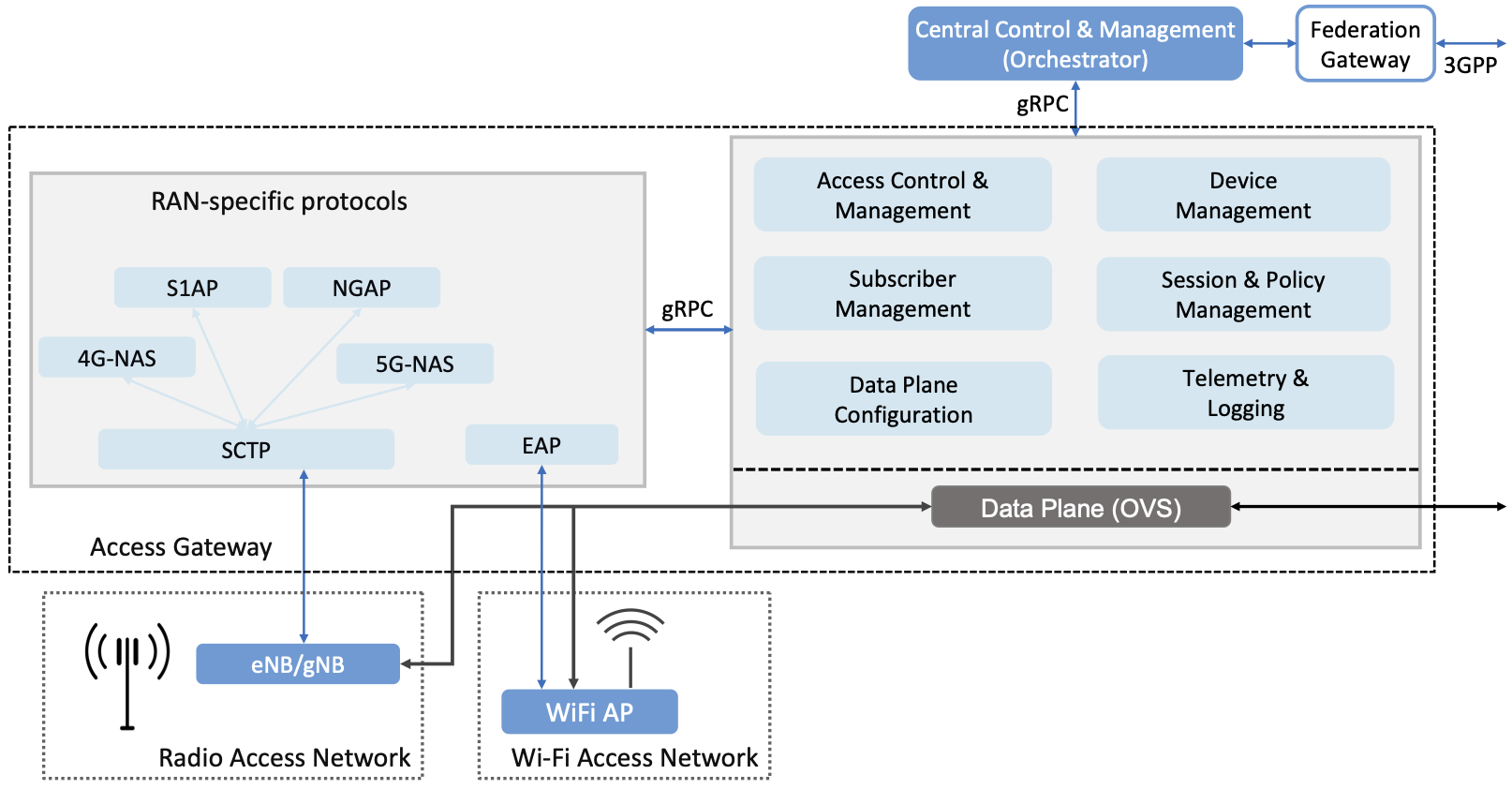
Figure 36. Overall architecture of the Magma Mobile Core, including support for 4G and 5G, and Wi-Fi. There is one central Orchestrator and typically many Access Gateways (AGWs).
Figure 36 shows the overall Magma architecture. The central part of Magma is the single box in the figure marked Central Control & Management (Orchestrator). This is roughly analogous to the central controller found in typical SDN systems, and provides a northbound API by which an operator or other software systems (such as a traditional OSS/BSS) can interact with the Magma core. The orchestrator communicates over backhaul links with Access Gateways (AGWs), which are the distributed components of Magma. A single AGW typically handles a small number of eNBs/gNBs. As an example, see Figure 37 which includes a single eNB and AGW located on a radio tower. In this example, a point-to-point wireless link is used for backhaul.
The AGW is designed to have a small footprint, so that small deployments do not require a datacenter’s worth of equipment. Each AGW also contains both data plane and control plane elements. This is a little different from the classic approach to SDN systems in which only the data plane is distributed. Magma can be described as a hierarchical SDN approach, as the control plane itself is divided into a centralized part (running in the Orchestrator) and a distributed part (running in the AGW). Figure 36 shows the distributed control plane components and data plane in detail. We postpone a general discussion of orchestration until Chapter 6.

Figure 37. A sample Magma deployment in rural Peru, showing (a) point-to-point wireless backhaul, (b) LTE radio and antenna, (c) ruggedized embedded PC serving as AGW, and (d) solar power and battery backup for site.
Magma differs from the standard 3GPP approach in that it terminates 3GPP protocols logically close to the edge, which in this context corresponds to two interface points: (1) the radio interface connecting Magma to an eNB or gNB (implemented by set of modules on the left side of the AGW in the figure) or the federation interface connecting Magma to another mobile network (implemented by the Federation Gateway module in the figure). Everything “between” those two external interfaces is free to deviate from the 3GPP specification, which has a broad impact as discussed below.
One consequence of this approach is that Magma can interoperate with other implementations only at the edges. Thus, it is possible to connect a Magma mobile core to any standards-compliant 4G or 5G base station and expect it to work, and similarly, it is possible to federate a Magma core with an existing MNO’s 4G or 5G network. However, since Magma does not implement all the 3GPP interfaces that are internal to a mobile packet core, it is not possible to arbitrarily mix and match components within the core. Whereas (in principle) a traditional 3GPP implementation would permit an AMF from one vendor to interoperate with the SMF of another vendor, it is not possible to connect parts of a mobile core from another vendor (or another open source project) with parts of Magma, aside from via the two interfaces just described.
Being free to deviate from the 3GPP spec means Magma can take a unifying approach across multiple wireless technologies, including 4G, 5G and WiFi. There is a set of functions that the core must implement for any radio technology (e.g., finding the appropriate policy for a given subscriber by querying a database); Magma provides them in an access-technology-independent way. These functions form the heart of an Access Gateway (AGW), as illustrated on the right side of Figure 36. On the other hand, control protocols that are specific to a given radio technology are terminated in technology-specific modules close to the radio. For example, SCTP shown on the left side of the figure is the RAN tunneling protocol introduced in Section 2.3. These technology-specific modules then communicate with the generic functions (e.g., subscriber management, access control and management) on the right using gRPC messages that are technology-agnostic.
Magma’s design is particularly well suited for environments where backhaul links are unreliable, for example, when a satellite is used. This is because the 3GPP protocols that traditionally have to traverse the backhaul from core to eNB/gNB are quite sensitive to loss and latency. Loss or latency can cause connections to be dropped, which in turn forces UEs to repeat the process of attaching to the core. In practice, not all UEs handle this elegantly, sometimes ending up in a “stuck” state.
Magma addresses the challenge of unreliable backhaul in several ways. First, Magma frequently avoids sending messages over the backhaul entirely by running more functionality in the AGW, which is located close to the radio as seen above. Functions that would be centralized in a conventional 3GPP implementation are distributed out to the access gateways in Magma. Thus, for example, the operations required to authenticate and attach a UE to the core can typically be completed using information cached locally in the AGW, without any traffic crossing the backhaul. Secondly, when Magma does need to pass information over a backhaul link (e.g., to obtain configuration state from the orchestrator), it does so using gRPC, which is designed to operate reliably in the face of unreliable or high-latency links.
Note that while Magma has distributed much of the control plane out to the AGWs, it still supports centralized management via the Orchestrator. For example, adding a new subscriber to the network is done centrally, and the relevant AGW then obtains the necessary state to authenticate that subscriber when their UE tries to attach to the network.
Finally, Magma adopts a desired state model for managing runtime and configuration state. By this we mean that it communicates a state change (e.g., the addition of a new session in the user plane) by specifying the desired end state via an API call. This is in contrast with the incremental update model that is common in the 3GPP specification. When the desired end state is communicated, the loss of a message or failure of a component has less serious consequences. This makes reasoning about changes across elements of the system more robust in the case of partial failures, which are common in challenged environments like the ones Magma is designed to serve.
Consider an example where we are establishing user plane state for a set of active sessions. Initially, there are two active sessions, X and Y. Then a third UE becomes active and a session Z needs to be established. In the incremental update model, the control plane would instruct the user plane to “add session Z”. The desired state model, by contrast, communicates the entire new state: “the set of sessions is now X, Y, Z”. The incremental model is brittle in the face of failures. If a message is lost, or a component is temporarily unable to receive updates, the receiver falls out of sync with the sender. So it is possible that the control plane believes that sessions X, Y and Z have been established, while the user plane has state for only X and Y. By sending the entire desired end state, Magma ensures that the receiver comes back into sync with the sender once it is able to receive messages again.
As described, this approach might appear inefficient because it implies sending complete state information rather than incremental updates. However, at the scale of an AGW, which handles on the order of hundreds to a few thousands of subscribers, it is possible to encode the state efficiently enough to overcome this drawback. With the benefit of experience, mechanisms have been added to Magma to avoid overloading the orchestrator, which has state related to all subscribers in the network.
The desired state approach is hardly novel but differs from typical 3GPP systems. It allows Magma to tolerate occasional communication failures or component outages due to software restarts, hardware failures, and so on. Limiting the scope of 3GPP protocols to the very edge of the network is what enables Magma to rethink the state synchronization model. The team that worked on Magma describes their approach in more detail in an NSDI paper.
Further Reading
S. Hasan, et al. Building Flexible, Low-Cost Wireless Access Networks With Magma. NSDI, April 2023.
Finally, while we have focused on its Control Plane, Magma also includes a User Plane component. The implementation is fairly simple, and is based on Open vSwitch (OVS). Having a programmable user plane is important, as it needs to support a range of access technologies, and at the same time, OVS meets the performance needs of AGWs. However, this choice of user plane is not fundamental to Magma, and other implementations have been considered. We take a closer look at the User Plane in the next section.
5.4 User Plane
The User Plane of the Mobile Core—corresponding to the UPF component in Figure 34—connects the RAN to the Internet. Much like the data plane for any router, the UPF forwards IP packets, but because UEs often sleep to save power and may be in the process of being handed off from one base station to another, it sometimes has to buffer packets for an indeterminate amount of time. Also like other routers, a straightforward way to understand the UPF is to think of it as implementing a collection of Match/Action rules, where the UPF first classifies each packet against a set of matching rules, and then executes the associated action.
Using 3GPP terminology, packet classification is defined by a set of Packet Detection Rules (PDRs), where a given PDR might simply match the device’s IP address, but may also take the domain name of the far end-point into consideration. Each attached UE has at least two PDRs, one for uplink traffic and one for downlink traffic, plus possibly additional PDRs to support multiple traffic classes (e.g., for different QoS levels, pricing plans, and so on.). The Control Plane creates, updates, and removes PDRs as UEs attach, move, and detach.
Each PDR then identifies one or more actions to execute, which in 3GPP terminology are also called “rules”, of which there are four types:
Forwarding Action Rules (FARs): Instructs the UPF to forward downlink packets to a particular base station and uplink traffic to a next-hop router. Each FAR specifies a set of parameters needed to forward the packet (e.g., how to tunnel downlink packets to the appropriate base station), plus one of the following processing flags: a forward flag indicates the packet should be forwarded up to the Internet; a tunnel flag indicates the packet should be tunneled down to a base station; a buffer flag indicates the packet should be buffered until the UE becomes active; and a notify flag indicates that the CP should be notified to awaken an idle UE. FARs are created and removed when a device attaches or detaches, respectively, and the downlink FAR changes the processing flag when the device moves, goes idle, or awakes.
Buffering Action Rules (BARs): Instructs the UPF to buffer downlink traffic for idle UEs, while also sending a Downlink Data Notification to the Control Plane. This notification, in turn, causes the CP to instruct the base station to awaken the UE. Once the UE becomes active, the UPF releases the buffered traffic and resumes normal forwarding. The buffering and notification functions are activated by modifying a FAR to include buffer and notify flags, as just described. An additional set of parameters are used to configure the buffer, for example setting its maximum size (number of bytes) and duration (amount of time). Optionally, the CP can itself buffer packets by creating a PDR that directs the UPF to forward data packets to the control plane.
Usage Reporting Rules (URRs): Instructs the UPF to periodically send usage reports for each UE to the CP. These reports include counts of the packets sent/received for uplink/downlink traffic for each UE and traffic class. These reports are used to both limit and bill subscribers. The CP creates and removes URRs when the device attaches and detaches, respectively, and each URR specifies whether usage reports should be sent periodically or when a quota is exceeded. A UE typically has two URRs (for uplink/downlink usage), but if a subscriber’s plan includes special treatment for certain types of traffic, an additional URR is created for each such traffic class.
Quality Enforcement Rules (QERs): Instructs the UPF to guarantee a minimum amount of bandwidth and to enforce a bandwidth cap. These parameters are specified on a per-UE / per-direction / per-class basis. The CP creates and removes QERs when a device attaches and detaches, respectively, and modifies them according to operator-defined events, such as when the network becomes more or less congested, the UE exceeds a quota, or the network policy changes (e.g., the user signs up for a new pricing plan). The UPF then performs traffic policing to enforce the bandwidth cap, along with packet scheduling to ensure a minimum bandwidth in conjunction with admission control in the control plane.
The rest of this section describes two complementary strategies for implementing a UPF, one server-based and one switch-based.
5.4.1 Microservice Implementation
A seemingly straightforward approach to supporting the set of Match/Action rules just described is to implement the UPF in software on a commodity server. Like any software-based router, the process would read a packet from an input port, classify the packet by matching it against a table of configured PDRs, execute the associated action(s), and then write the packet to an output port. Such a process could then be packaged as a Docker container, with one or more instances spun up on a Kubernetes cluster as workload dictates. This is mostly consistent with a microservice-based approach, with one important catch: the actions required to process each packet are stateful.
What we mean by this is that the UPF has two pieces of state that needs to be maintained on a per-UE / per-direction / per-class basis: (1) a finite state machine that transitions between forward, tunnel, buffer, and notify; and (2) a corresponding packet buffer when in buffer state. This means that as the UPF scales up to handle more and more traffic—by adding a second, third, and fourth instance—packets still need to be directed to the original instance that knows the state for that particular flow. This breaks a fundamental assumption of a truly horizontally scalable service, in which traffic can be randomly directed to any instance in a way that balances the load. It also forces you to do packet classification before selecting which instance is the right one, which can potentially become a performance bottleneck, although it is possible to offload the classification stage to a SmartNIC/IPU.
5.4.2 P4 Implementation
Since the UPF is fundamentally an IP packet forwarding engine, it can also be implemented—at least in part—as a P4 program running on a programmable switch. Robert MacDavid and colleagues describe how that is done in SD-Core, which builds on the base packet forwarding machinery described in our companion SDN book. For the purposes of this section, the focus is on the four main challenges that are unique to implementing the UPF in P4.
Further Reading
R. MacDavid, et al. A P4-based 5G User Plane Function. Symposium on SDN Research, September 2021.
Software-Defined Networks: A Systems Approach. November 2021.
First, P4-programmable forwarding pipelines include an explicit “matching” mechanism built on Ternary Content-Addressable Memory (TCAM). This memory supports fast table lookups for patterns that include wildcards, making it ideal for matching IP prefixes. In the case of the UPF, however, the most common PDRs correspond to exact matches of IP addresses (for downlink traffic to each UE) and GTP tunnel identifiers (for uplink traffic from each UE). More complex PDRs might include regular expressions for DNS names or require deep packet inspection.
Because TCAM capacity is limited, and the number of unique PDRs that need to be matched in both directions is potentially in the tens of thousands, it’s necessary to use the TCAM judiciously. One implementation strategy is to set up two parallel PDR tables: one using the relatively plentiful switch SRAM for common-case uplink rules that exactly matches on tunnel identifiers (which can be treated as table indices); and one using TCAM for common-case downlink rules that match the IP destination address.
Second, when a packet arrives from the Internet destined for an idle UE, the UPF buffers the packet and sends an alert to the 5G control plane, asking that the UE be awakened. Today’s P4-capable switches do not have large buffers or the ability to hold packets indefinitely, but a buffering microservice running on a server can be used to address this limitation. The microservice indefinitely holds any packets that it receives, and later releases them back to the switch when instructed to do so. The following elaborates on how this would work.
When the Mobile Core detects that a UE has gone idle (or is in the middle of a handover), it creates a FAR with the buffer flag set, causing the on-switch P4 program to redirect packets to the buffering microservice. Packets are redirected without modifying their IP headers by placing them in a tunnel, using the same tunneling protocol that is used to send data to base stations. This allows the switch to treat the buffering microservice just like another base station.
When the first packet of a flow arrives at the buffering microservice, it sends an alert to the CP, which then (1) wakes up the UE, (2) modifies the corresponding FAR by unsetting the buffer flag and setting the tunnel flag, and once the UE is active, (3) instructs the buffering microservice to release all packets back to the switch. Packets arriving at the switch from the buffering microservice skip the portion of the UPF module they encountered before buffering, giving the illusion they are being buffered in the middle of the switch. That is, their processing resumes at the tunneling stage, where they are encapsulated and routed to the appropriate base station.
Third, QERs cannot be fully implemented in the switch because P4 does not include support for programming the packet scheduler. However, today’s P4 hardware does include fixed-function schedulers with configurable weights and priorities; these parameters are set using a runtime interface unrelated to P4. A viable approach, similar to the one MacDavid, Chen, and Rexford describe in their INFOCOM paper, is to map each QoS class specified in a QER onto one of the available queues, and assign a weight to that queue proportional to the fraction of the available bandwidth the class is to receive. As long as each class/queue is not over subscribed, individual UEs in the class will receive approximately the bit rate they have been promised. As an aside, since 3GPP under-specifies QoS guarantees (leaving the details to the implementation), such an approach is 3GPP-compliant.
Further Reading
R. MacDavid, X. Chen, J. Rexford. Scalable Real-time Bandwidth Fairness in Switches. IEEE INFOCOM, May 2023.
Finally, while the above description implies the Mobile Core’s CP talks directly to the P4 program on the switch, the implementation is not that straightforward. From the Core’s perspective, the SMF is responsible for sending/receiving control information to/from the UPF, but the P4 program implementing the UPF is controlled through an interface (known as P4Runtime or P4RT) that is auto-generated from the P4 program being controlled. MacDavid’s paper describes how this is done in more detail (and presumes a deep understanding of the P4 toolchain), but it can be summarized as follows. It is necessary to first write a “Model UPF” in P4, use that to program to generate the UPF-specific P4RT interface, and then write translators that (1) connect SMF to P4RT, and (2) connect P4RT to the underlying physical switches and servers. A high-level schematic of this software stack is shown in Figure 38.
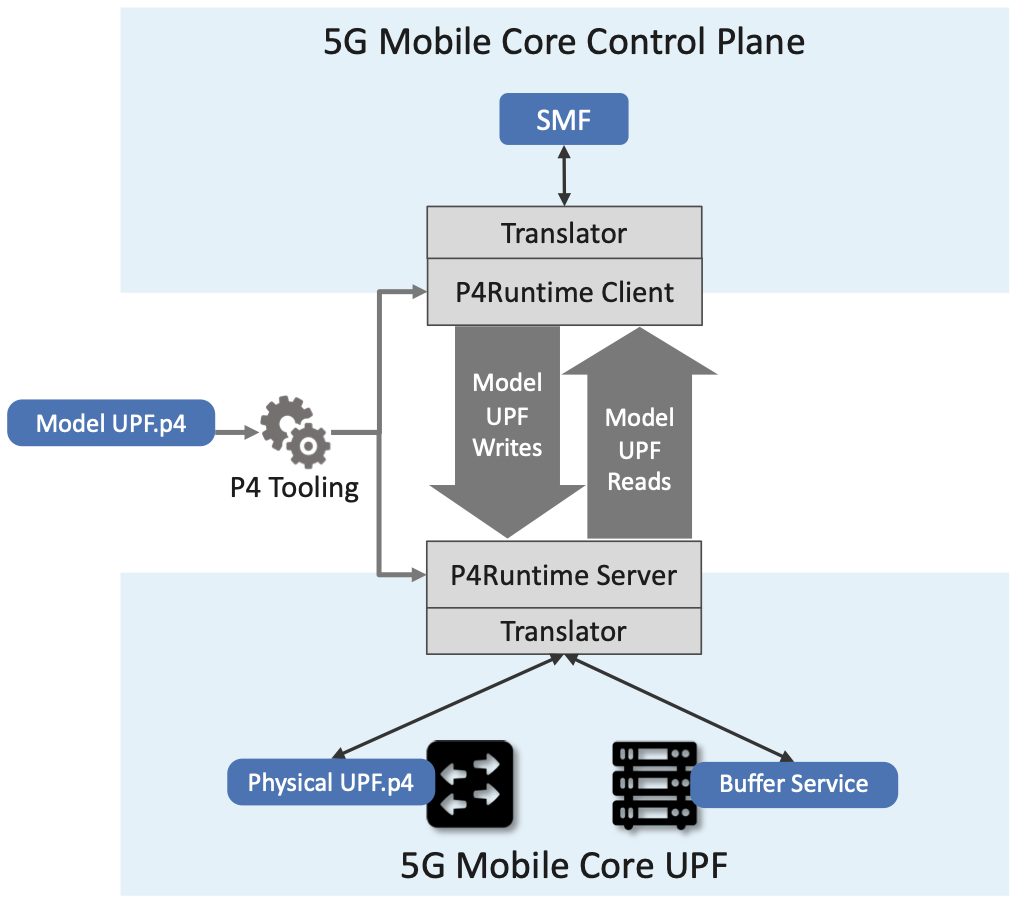
Figure 38. A model P4-based implementation of the UPF is used to generate the interface that is then used by the SMF running in the Mobile Core control plane to control the physical implementation of the UPF running on a combination of hardware switches and servers.
Note that while this summary focuses on how the CP controls the UPF (the downward part of the schematic shown in Figure 38), the usage counters needed to generate URRs that flow upward to the CP are easy to support because the counters implemented in the switching hardware are identical to the counters in the Model UPF. When the Mobile Core requests counter values from the Model UPF, the backend translator polls the corresponding hardware switch counters and relays the response.